1682: K-means 算法
内存限制:128 MB
时间限制:1 S
题面:传统
评测方式:文本比较
上传者:
提交:6
通过:4
题目描述
题目描述
K-means 算法是无监督学习中经典的聚类算法,其核心思想是将 n 个 d 维样本点划分为 K 个聚类,使得每个聚类内的样本点到该聚类中心的距离之和最小。现要求你实现标准 K-means 算法,具体规则如下:
- 初始聚类中心:选择输入数据中前 K 个样本点作为初始聚类中心。
- 距离度量:使用欧几里得距离的平方(避免浮点精度损失,公式:dist2=∑i=1d(xi−yi)2)。
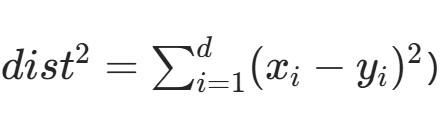
- 样本分配:将每个样本点分配到距离其最近的聚类中心所属的聚类。
- 中心更新:每个聚类的新中心为该聚类内所有样本点各维度的均值;若某聚类无样本(空聚类),则重新选择该聚类的中心为距离当前所有聚类中心最远的样本点。
- 收敛条件:若所有聚类中心的位置变化的欧几里得距离平方之和小于给定阈值ε,则停止迭代;若未收敛但达到最大迭代次数 T,也停止迭代。
请你实现该算法,并输出最终的 K 个聚类中心(按聚类编号 0~K-1 输出)。
输入格式
第一行包含 5 个参数:
- n:样本点数量(1≤n≤104)
- d:样本点的维度(1≤d≤10)
- K:聚类数量(1≤K≤min(n,100))
- T:最大迭代次数(1≤T≤100)
- ε:收敛阈值(0<ε≤10−3,浮点数)
接下来 n 行,每行包含 d 个浮点数,表示一个 d 维样本点(每个数值范围[−104,104])。
输出格式
输出 K 行,每行包含 d 个浮点数,表示最终的聚类中心(聚类编号 0~K-1),每个数值保留 6 位小数。
输入样例 复制
6 2 2 100 1e-6
1.0 1.0
2.0 2.0
1.5 1.5
8.0 8.0
9.0 9.0
8.5 8.5输出样例 复制
1.500000 1.500000
8.500000 8.500000